Hierarchical Feature Selection
Idea
Using the Generators provided in this package will often result in a lot of attributes. Thus, it can be benificial to filter the attributes before performing further analysis. Besides standard feature selection methods (e.g. removing correlated attributes, attributes with many missings, or attributes with little variation) that might be usefull for this task, this package comes with a collection of feature selection approaches, that work by exploiting the semantics of Linked Open Data sources to filter the attributes created by the generators.
Note
For the provided Feature Selection algorithms work only with the following generators:
Also, for them to work you need a Label Column in your data which can be used by the algorithms to evaluate the predictive power of the features.
Theorectical Background
Basics
Before hierarchical feature selection can be performed, first a hierarchy graph needs to be built. The graph contains the hierarchical dependencies of all attributes that were created by a generator. The hierarchy graph is created by recursively querying a selected hierarchy relation (by default the rdfs:subClassOf property). The process starts by first querying the selected hierarchy relation for each of the generated attribute. It then continues to query the resulting superclasses for theirs superclasses, until a full hierarchy tree was created.
Example
Imagine we have a dataset containing tweets, which is supposed to be used for topic classification. We alread extracted all types of the DBpedia concept discovered in each tweet using the Direct Type Generator. In the same step we also already extracted a hierarchy graph as the hierarchy argument was set to True. The resulting hierarchy graph is already embedded into the DataFrame returned by the generator.
In Fig. 1 you can see a small part of the extracted hierarchy graph. Based on this example, we can explain why it can make sense to perform Hierarchical Feature Selection.
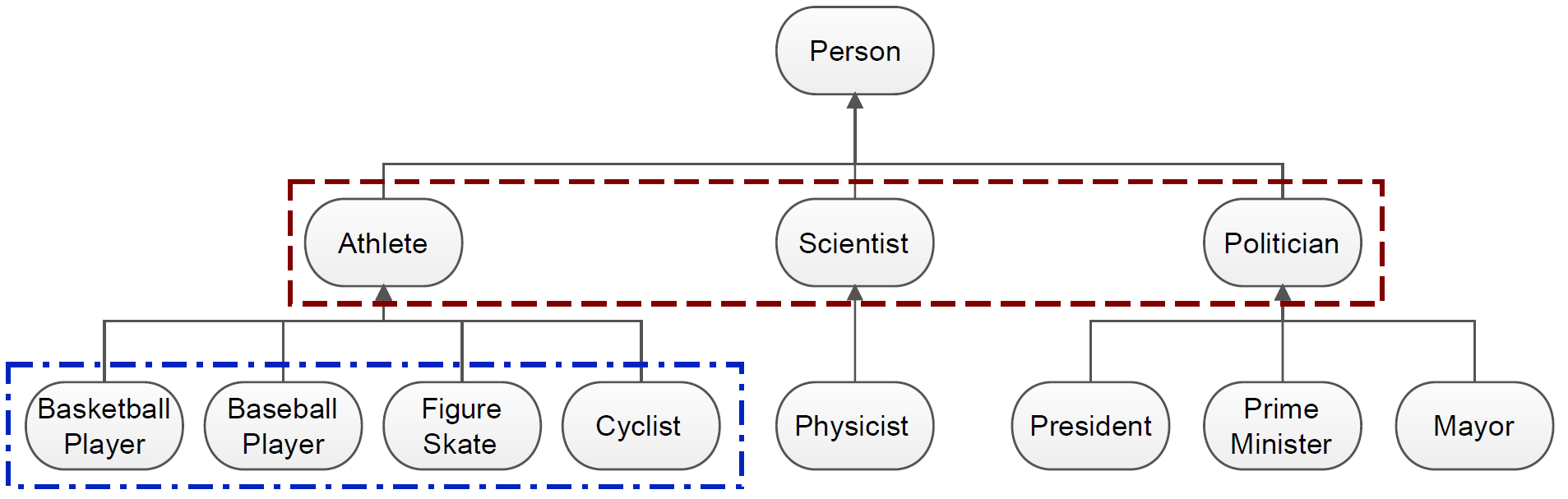
Fig. 1 Small part of the hierarchy graph extracted for the Twitter dataset. [RP14].
If, for instance, the task would be to classify tweets into sports related and non sports related, the optimal features would be those in the upper rectangle. However, if the task would be to classify the tweets by different kinds of sports, then the features in the lower rectangle would be more valuable.
Hierarchical Feature Selection is about automating the discovery of these patterns of relevant features.
Provided Approaches
All provided approaches aim to, in one way or another, reduce the amount of redundant features by examining the hierarchical structure between the generated features, as well as the predictive power of the features based on some metric (e.g. information gain).
This package includes the following approaches:
Hill Climbing Filter (HC): Hill Climbing is a bottom up approach which uses the purity of nearest neighbors of all instances in a dataset to assign scores to attributes. Paper: [WMAB03]
Tree Based Filter (TSEL): TSEL selects the most valuable attributes from each branch in the hiearchy, based on information gain or lift. Paper: [JM13]
Hierarchy Based Filter (SHSEL): SHSEL eliminates redundant attributes along hierarchy paths, while pruneSHSEL further reduces the feature set by selecting only the most relevant attributes of the reduced hierarchy. For both algorithms, the underlying relevance measure can be correlation or information gain. Paper: [RP14]
Greedy Top Down Filter (GTD): Greedy top down selects attributes that have a high information gain ratio, while pruning those attributes that are adjacent to the selected ones in the hierarchy. Paper: [LYT+13]
Note
This overview was taken from [PRMB14].
A detailed comparison and evaluation on the filtering algorithms can be found in [RP14].
Usage
Preparation
For the provided Feature Selection algorithms to work you need a hierarchy graph of the generated attributes. As mentioned above, the creation of this graph is only supported by the following generators:
To create a hierarchy graph it is sufficient to set the hierarchy argument of these generators to True, as in this example:
from kgextension.generator import direct_type_generator
data_expanded = direct_type_generator(data_linked, "new_link", hierarchy=True)
The resulting hierarchy graph is appended to the result DataFrame returned by the generator and can, if of interest, be accessed as follows:
data_expanded.attrs["hierarchy"]
Hill Climbing Filter (HC)
To perform Hierarchical Feature Selection using the Hill Climbing Filter, you simply call the hill_climbing_filter() method, as in the following minimal example:
from kgextension.feature_selection import hill_climbing_filter
data_filtered = hill_climbing_filter(data_expanded, "class")
The data_expanded DataFrame is the one created in Preparation.
Tree Based Filter (TSEL)
To perform Hierarchical Feature Selection using the Tree Based Filter, you simply call the tree_based_filter() method, as in the following minimal example:
from kgextension.feature_selection import tree_based_filter
data_filtered = tree_based_filter(data_expanded, "class")
The data_expanded DataFrame is the one created in Preparation.
Hierarchy Based Filter (SHSEL)
To perform Hierarchical Feature Selection using the Hierarchy Based Filter, you simply call the hierarchy_based_filter() method, as in the following minimal example:
from kgextension.feature_selection import hierarchy_based_filter
data_filtered = hierarchy_based_filter(data_expanded, "class")
The data_expanded DataFrame is the one created in Preparation.
Greedy Top Down Filter (GTD)
To perform Hierarchical Feature Selection using the Greedy Top Down Filter, you simply call the greedy_top_down_filter() method, as in the following minimal example:
from kgextension.feature_selection import greedy_top_down_filter
data_filtered = greedy_top_down_filter(data_expanded, "class")
The data_expanded DataFrame is the one created in Preparation.
- JM13
Yoonjae Jeong and Sung-Hyon Myaeng. Feature selection using a semantic hierarchy for event recognition and type classification. In Proceedings of the Sixth International Joint Conference on Natural Language Processing, 136–144. Nagoya, Japan, October 2013. Asian Federation of Natural Language Processing. URL: https://www.aclweb.org/anthology/I13-1016.
- LYT+13
Sisi Lu, Ye Ye, Rich Tsui, Howard Su, Ruhsary Rexit, Sahawut Wesaratchakit, Xiaochu Liu, and Rebecca Hwa. Domain ontology-based feature reduction for high dimensional drug data and its application to 30-day heart failure readmission prediction. In 9th IEEE International Conference on Collaborative Computing: Networking, Applications and Worksharing. ICST, 11 2013. doi:10.4108/icst.collaboratecom.2013.254124.
- PRMB14
Heiko Paulheim, Petar Ristoski, Evgeny Mitichkin, and Christian Bizer. RapidMiner Linked Open Data Extension - Manual - Version 1.5. 2014. [Accessed: 2020-05-19].
- RP14(1,2,3)
Petar Ristoski and Heiko Paulheim. Feature selection in hierarchical feature spaces. In Saso Dzeroski, editor, Discovery Science : 17th International Conference, DS 2014, Bled, Slovenia, October 8-10, 2014. Proceedings, volume 8777, 288–300. Cham, 2014. Springer Internat. Publ. URL: https://madoc.bib.uni-mannheim.de/37063/, doi:10.1007/978-3-319-11812-3\_25.
- WMAB03
Bill B. Wang, R. I. Bob Mckay, Hussein A. Abbass, and Michael Barlow. A comparative study for domain ontology guided feature extraction. In Proceedings of the 26th Australasian Computer Science Conference - Volume 16, ACSC '03, 69–78. AUS, 2003. Australian Computer Society, Inc.